3天通关PyTorch三域实战:深度学习+大模型+AIGC
本文将带你快速理解:PyTorch是什么、它有哪些核心“黑科技”、它与TensorFlow有何不同,以及如何用它开启你的AI之旅。
是不是一提到人工智能专业知识,就感觉脑袋嗡嗡的?
那些复杂的算法、抽象的理论,还有层出不穷、让人眼花缭乱的框架名称...是不是让你望而却步?
想踏入人工智能这个充满魅力的领域,却不知道从哪儿开始?好不容易鼓起勇气学起来,又常常在各种框架的迷宫里晕头转向,学得一头雾水?这滋味,太难受啦!
别担心!今天,我们就来一起解锁一个强大又好用的工具——PyTorch!
掌握它,你就能快速推开深度学习这扇大门!本文将带你快速理解:PyTorch是什么、它有哪些核心“黑科技”、它与TensorFlow有何不同,以及如何用它开启你的AI之旅。

目录
三、PyTorch vs TensorFlow:谁更适合你?
一、PyTorch:你的深度学习“万能工具箱”
简单来说,PyTorch 是一个基于 Torch 库开发的开源 Python 机器学习库。它由 Meta(原 Facebook)的 AI 团队主导开发,现已成为 Linux 基金会下的重要项目。
为了让你更好理解,我们来打个比方:
想象一下,你想用代码计算一个数的平方根。键盘上可没有直接的“√”键能让计算机明白你的意思。这时,你会调用 Python 的 math.sqrt() 函数。math 库就像一个“数学百宝箱”,里面装满了预先写好的、能让计算机执行复杂数学计算的指令。
PyTorch,就如同一个超级升级版的 math 库,但它专精于深度学习!它集成了海量强大的工具,专门用来解决构建、训练和部署深度神经网络模型过程中的各种难题。
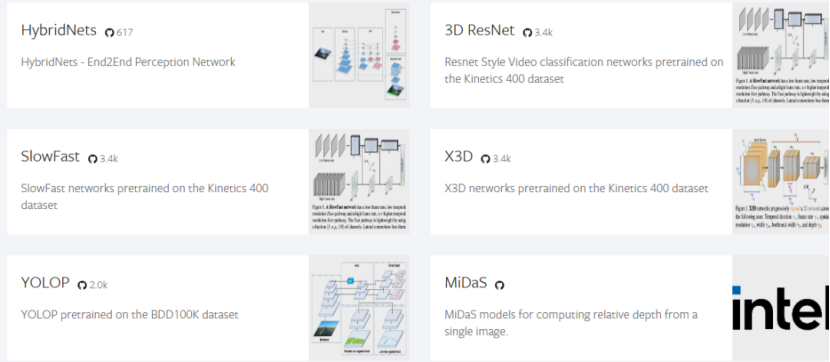
好比这张图中,这些模型都是由Pytorch搭建出来的。
深度学习的理论本身复杂精深,充满了数学推导和算法设计。这就好比你要建造一座摩天大楼,深度学习理论是那套精密的建筑设计蓝图。而 PyTorch,就是那一整套高效、趁手、现代化的建筑工具和施工设备。
有了PyTorch,我们就能利用它提供的各种“工具”——比如张量操作(Tensor Operations)、灵活的模型构建模块(nn.Module)、以及神奇的自动求导(Autograd) ——来把学到的神经网络架构知识,像搭积木一样,顺畅地转化为可运行的代码,最终构建出强大的AI模型。
二、四大核心“黑科技”,让深度学习触手可及
PyTorch 能成为研究者和开发者的宠儿,离不开它几项强大的核心技术:
1. 动态计算图:像搭乐高一样灵活构建模型
当我们将目光聚焦到 PyTorch 的技术内核,首先映入眼帘的便是其独特的动态计算图机制。与 TensorFlow 的 “先编译后执行” 模式截然不同,PyTorch 的计算图在程序运行期间实时生成。

图片来自GitHub上的Pytorch
这就像厨师在烹饪过程中,可以根据食材的状态和口味需求,随时调整菜谱和步骤。在模型训练和调试阶段,开发者可以随心所欲地修改网络结构、调整计算流程、插入调试语句,整个过程“所见即所得”,极大地提升了调试效率。
2.自动微分:解放双手的“梯度计算引擎”
在深度学习模型训练里,梯度计算至关重要,而 PyTorch 的 autograd 模块堪称处理这一任务的得力助手。它就像一位智能管家,默默在后台自动追踪所有张量操作。
当开发者在模型中调用.backward()方法时,autograd 模块会迅速构建计算图,并精准地计算出梯度。如此一来,研究人员无需再耗费大量精力手动推导复杂的数学公式,极大地减轻了工作负担。
3.张量计算:从 CPU 到 GPU 的无缝切换
作为 AI 模型的基础数据结构,PyTorch 的张量(Tensor)发挥着不可替代的作用。它不仅支持类似 NumPy 的便捷操作,让习惯使用 NumPy 的开发者能够快速上手,更具备一项强大的能力 —— 能够在 CPU 和 GPU 之间轻松迁移。

只需简单的一行代码,就能实现从单卡到多卡的分布式训练,瞬间让模型的运算性能实现质的飞跃。
def commonType(Tensor):
if torch.cuda.is_available():
cuda = "cuda:0"
return Tensor.cuda(cuda)
else:
return Tensor4.模块化 API:开箱即用的深度学习工具箱
torch.nn 模块为开发者提供了多达 200 余种预定义的网络组件,从常见的卷积层到循环层,一应俱全;torch.optim 模块则内置了 Adam、SGD 等 10 多种优化算法。
 再加上 torchvision(计算机视觉领域)、torchaudio(语音处理领域)等丰富的生态库,这些工具相互配合,使得开发者能够在短时间内搭建出行业级别的 AI 模型,大大加快了开发进程。
再加上 torchvision(计算机视觉领域)、torchaudio(语音处理领域)等丰富的生态库,这些工具相互配合,使得开发者能够在短时间内搭建出行业级别的 AI 模型,大大加快了开发进程。
三、PyTorch vs TensorFlow:谁更适合你?
PyTorch:以其动态图、Pythonic 的直观设计、卓越的灵活性著称,在学术界和研究领域占据主导地位,是快速实验和原型设计的首选。学习曲线相对平缓,调试友好。
TensorFlow (尤其是 TF2.x + Keras):早期以静态图和高性能部署闻名。TF2.x 拥抱了动态图(Eager Execution)并深度集成 Keras API,大大提升了易用性。在工业界生产环境部署、移动端和边缘设备支持方面有深厚积累和成熟方案。
简单来说:喜欢灵活、直观、快速迭代做研究?PyTorch 可能是你的最佳拍档。需要将复杂模型部署到大规模生产系统或资源受限设备?TensorFlow 的成熟方案值得深入探索。
当然,两者都在不断进化,互相借鉴优点(如 PyTorch 强化部署,TensorFlow 提升易用性),选择哪个往往取决于具体项目需求、团队熟悉度和个人偏好。掌握其中一个,再了解另一个,是AI工程师的必备技能。
四、启程:如何用PyTorch推开深度学习大门?
学习 PyTorch 的最佳路径通常是:
1.打好基础
熟悉 Python 编程和基本的机器学习概念。
2.理解核心概念
重点掌握 Tensor(数据基石)、autograd(梯度核心)、nn.Module(模型骨架)和优化器(训练动力)。
3.动手实践
-从基础的张量操作开始。尝试用 nn.Module 构建一个简单的全连接网络(如MNIST手写数字识别)。
-理解并编写训练循环(前向传播、计算损失、反向传播 .backward()、优化器更新 .step())。
-逐步挑战更复杂的模型(CNN处理图像,RNN/LSTM处理序列)。
4.利用资源
官方教程、文档、优秀的在线课程(如 PyTorch 官网 Tutorials, fast.ai, Udacity/PyTorch Scholaship 等)、开源项目和活跃的社区(论坛、Stack Overflow)都是强大的助力。
结语
别再让复杂的理论和框架迷宫阻挡你探索人工智能的脚步!PyTorch 就是你手中那把打开深度学习大门的金钥匙。 它的动态计算图让你像搭积木一样自由构建模型,自动微分引擎默默为你扫清数学障碍,模块化设计让代码清晰优雅,强大的生态系统支持你从创意走向落地。
与其在门口徘徊,不如现在就开始动手! 从第一个 PyTorch Tensor 开始,从第一行简单的神经网络代码敲起,你将亲身感受到:深度学习,原来可以如此直观、灵活且充满乐趣! 踏上 PyTorch 之旅,开启你的 AI 创造时代吧!

聚焦前沿AI与大模型技术探索,汇聚开发者及爱好者,共享开源项目、学习资源与行业资讯。
更多推荐


 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

{kind=link}
所有评论(0)